ChatGPT,Bard,还是Bing?4万人投票选出最佳生成性人工智能模型
- 电脑快讯
- 1年前
- 183
- 更新:2024-01-25 16:42:16

使用ChatGPT可能会导致有用信息和荒谬答案的混合,这使得评估聊天机器人的整体性能变得困难。而制造生成性人工智能工具的公司,包括OpenAI、谷歌和微软,对他们使用的数据和他们的人工智能模型真正如何工作都是保密的。
如何测试聊天机器人
为了更多地了解生产性人工智能工具,加州大学伯克利分校与加州大学圣地亚哥分校(UCSD)和卡内基梅隆大学(CMU)合作,成立了一个名为大型模型系统组织(LMSYS Org)的组织。它由人工智能研究和计算机科学系的10名学生和4名教职员工组成。LMSYS Org创建了一项名为“聊天机器人竞技场”的实验,这是一个定制网站,任何人都可以在这里同时与两名模特匿名聊天。
一旦用户对他们更喜欢哪个聊天机器人的答案形成了看法,他们就会投票给最喜欢的聊天机器人,然后才能知道他们在和哪些模特交谈。该网站使用了支持ChatGPT和其他公司的相同的大型语言模型(LLM),并将LLM重新打包到一个新的界面中,因为OpenAI等公司已经公开提供了这些LLM。该网站还包含由个人创作的较小模型。

加州大学伯克利分校教授张浩(Oens In A New Window)是该项目的共同负责人之一,他表示:“我们之所以开始这样做,是因为我们在4月份基于Meta的骆驼模型创建了自己的人工智能模型,我们希望训练不同的版本,并对其进行迭代。”“它主要衡量的是人类的喜好,以及它遵循指令和完成人类想要的任务的能力,这是使模型有用的一个非常重要的因素。”
张说,该组织正在稳步向竞技场添加更多的模特,自4月份以来,已有约4万人参加。
聊天机器人竞技场
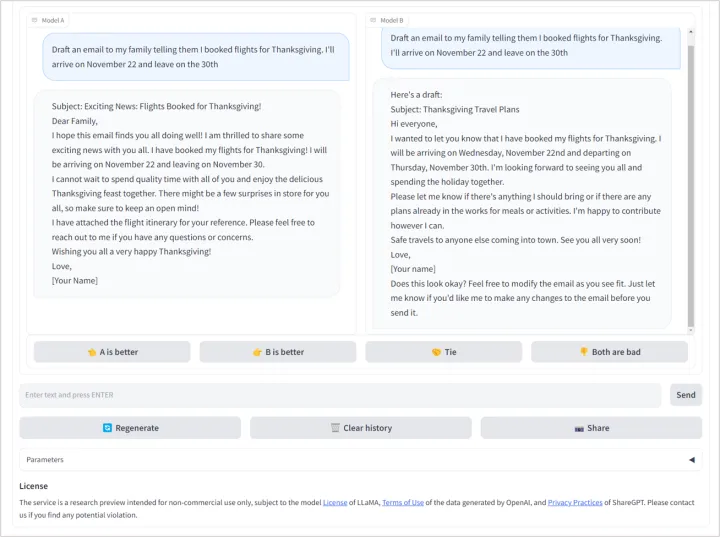
我们尝试了聊天机器人竞技场,如下所示。由于不知道页面为我们选择了哪两个人工智能模型进行比较,我们要求两人都“起草一封电子邮件给我的家人,告诉他们我已经预订了感恩节的机票,11月22日到达,11月30日离开。”每个人都生成了一封建议的电子邮件。我们选择了模型B作为首选选项。
然后,页面显示,模特B是克劳德,这是由Anthropic(在新窗口中打开)制作的AI助手。模型A被称为gpt4all-13b-snoozy(在新窗口中打开),由nomic AI(在新窗口中打开)构建。
LMSYS Org的一篇博客文章(在一个新窗口中打开)说,该网站考虑到每个用户的投票,使用Elo系统创建评级,这是一种在国际象棋和其他竞技游戏中广泛使用的评级系统。
费德里科·帕斯夸尔说:“我在多个受人尊敬的研究网站上都看到过这样的排行榜。”费德里科·帕斯夸尔之前曾在“拥抱脸”网站工作,该公司拥有自己的定制人工智能模型排行榜(在一个新窗口中打开)。“这是一个活跃的研究领域,因为人们正在想办法评估这些模型。三个月或六个月后,(聊天机器人竞技场排行榜)可能会看起来不一样。”
获胜者是..。
ChatGPT最先进的机型GPT-4目前以1225的ELO评级位居榜首。它可以在ChatGPT Plus账户上使用(每月20美元)。接下来,由人类制作的两个版本的克劳德分别位居第二(1195)和第三(1153)。克劳德目前可以通过等待名单获得;我们可以在几周内开始使用它。
免费版本的ChatGPT排名第四,其型号为GPT-3.5(1143)。OpenAI建议将GPT-3.5用于大多数日常任务,因为它比GPT-4运行得更快,而且仍然非常强大。出于这个原因,付费版上也有这款手机。但请注意,微软新的Bing AI Search是免费的,也可以在GPT-4上运行(在新窗口中打开)。
有话要说...