英特尔在Computex上展示“流星湖”处理器:人工智能占据中心舞台
- 电脑快讯
- 1年前
- 131
- 更新:2024-01-25 16:30:20
台北–2022年,英特尔提出了VPU的概念,这是一种用于其即将到来的“流星湖”处理器的新硅组件。在台北举行的仅限受邀参加的活动上,这家CPU巨头展示了第一款运行中的流星湖处理器,分享了更多关于这些下一代芯片的细节,并谈论了他们在当今最热门的领域:人工智能的能力。VPU将是这一目标的核心。
英特尔副总裁兼客户人工智能总经理约翰·雷菲尔德在Computex之前的周末会见了一群精选的记者,用第一款配备VPU的Meteor Lake芯片进行了几个演示,以揭开封面。流星湖芯片的确切型号,以及它的详细速度和馈送,都没有透露。然而,有一点是明确的,那就是流星湖将起源于移动市场。这是因为新的VPU模块完全是关于能效的,并将苛刻的人工智能相关任务放在这个新的处理组件上。
什么是流星湖?
英特尔的下一代处理器被戏称为这个最新的“Lake”代号,英特尔在演示中阐述了围绕它的几个原则。上一代Alder Lake(第12代核心)和Raptor Lake(第13代核心)通过其混合设计强调性能,芯片上有新的高性能核心(P-核心)和高效核心(E-核心)。这几代产品在IPC、频率和性能功耗比方面都有所提高。

在开发过程中,英特尔与微软做了大量工作,以确保其处理器将任务转移到适当的核心,这在Windows 11和英特尔的线程导向器工具中得到了体现。更进一步,Meteor Lake将从一开始就强调通过结合新的工艺技术和在Meteor Lake的新的模块化芯片设计中增加VPU来提高能效,采用了大致被称为“芯片”或“瓷砖”的设计。
当然,让软件与新的处理器组件配合得很好是一个诀窍,但与Alder和Raptor Lake的合作意味着可以带来一个大型应用生态系统;ISV支持已经到位,根据Rayfield的说法,英特尔的优势在于巨大的x86应用基础。
向VPU迁移的部分原因是英特尔的Foveros技术(更多信息请参见链接)和2016年收购芯片制造商Movidius的成果。简而言之,Foveros采用了3D堆叠技术,允许芯片模块或芯片组分层,而不是并排布局。在流星湖的案例中,其中一个模块将是VPU,这家芯片巨头表示,VPU将是这一代的秘密酱汁。
《流星湖基础知识:早期》
英特尔尚未透露任何有关流星湖芯片的信息。正如去年在热芯片大会上的一次演示中指出的那样,流星湖将在Intel 4工艺上生产(与Alder和Raptor Lake使用的Intel 7工艺形成对比)。下一代《箭湖》将采用英特尔的20A流程。需要提醒的是,其工艺名称中“Intel”后面的数字不再对应于工艺技术中的纳米尺寸。
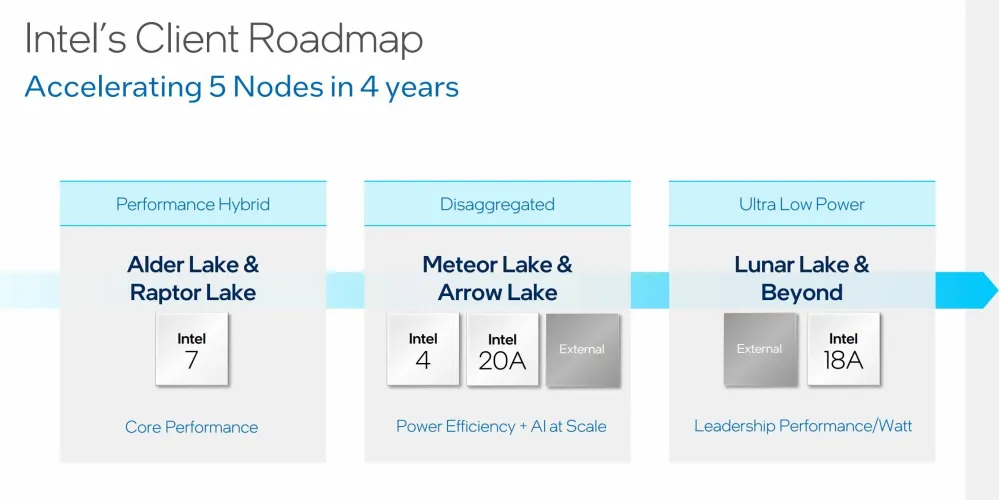
在英特尔4上加大流星湖的开发力度,该公司强调下一代电源管理和超高效。流星湖还将采用英特尔的最新版本的芯片图形,这将是基于英特尔Arc,在这种情况下,Arc的“炼金术士”架构。Arc集成将带来对关键技术的支持,如DirectX 12旗舰版、XeSS(超级采样)和低功耗格式的光线跟踪。英特尔代表不愿透露更多关于芯片上Arc的细节,但坚称图形加速将比英特尔现有的集成图形(IGP)解决方案好得多。Arc IGP将无法在原始性能方面与英特尔的Arc台式机卡相比,因为功率包络非常不同,但它将是相同的设计作为芯片,在较低的热量下运行。

然而,VPU将成为这里迄今为止最大的发展,其任务是在PC上进行本地推理。Rayfield甚至强调,这是PC领域的一个分水岭时刻,整合了高效的本地客户端AI处理以及这将使之成为可能的东西。他说:“我们正在扭转个人电脑的这一局面,界面将发生根本性的变化。”“未来5年,用户界面将发生比过去20年更大的变化……以一种好的方式。”
VPU关心吗?为什么英特尔的新磁贴很重要
英特尔认为自己处于利用人工智能的理想位置,并随着技术的发展为有用的最终用户体验奠定基础。雷菲尔德指出,首先,当人工智能集成到用户界面中时,延迟是人工智能的一个问题。根据过去的计算经验,用户希望获得即时响应,而基于云的解决方案根本无法与之匹敌。此外,将ChatGPT等人工智能应用程序扩展到数百万PC用户的成本也面临着根本性的挑战。与将部分处理负载放在客户端相比,这样做成本太高。在本地执行一些工作可以实现大规模分布式扩展、更好地控制隐私(您的数据保留在本地)和低延迟(计算在您的设备上进行)。
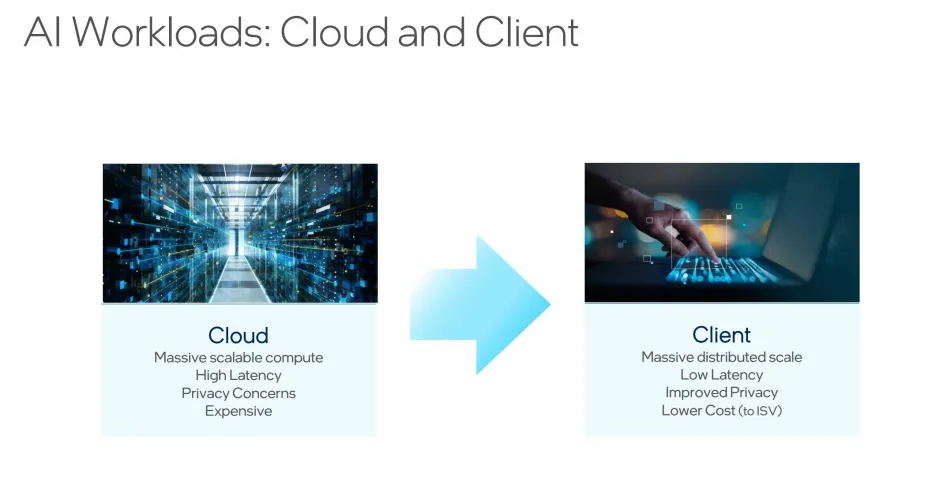
在目前的计算条件下,这实际上是如何发挥作用的?如今,人工智能被用于客户端平台,用于视频通话中的实时背景替换和模糊处理,以及动态降噪。这些任务使用在CPU和GPU上工作的推理模型;随着效果变得更大,用户期望变得更高,计算问题变得更加苛刻,电力使用也可能成为问题。尽管如此,像ChatGPT和稳定扩散(在新窗口中打开)这样更突出、更可识别的人工智能形式正在席卷世界,它们都是基于云的。Rayfield引用了一些统计数据,表明从2021年到2023年,动态噪音抑制的计算能力需求增加了50倍,基于大型语言模型(LLMS)的生成性人工智能工作的需求甚至获得了更大的收益,微软的联合飞行员就是一个例子。这些飞涨的需求意味着将部分需求转移到低功率水平的本地推理上的潜力很大。

在流星湖上以瓦片形式到达的VPU是神经加速器。CPU和GPU仍将获得自己的任务,这将仍然是一个异构的平台,但将负载放在VPU上处理繁重的AI任务有重大优势。也就是说,一些较小的人工智能相关任务仍将由CPU部分逐一处理,如果不值得通过设备驱动程序来处理这些任务的话。

虽然英特尔在过去几年与微软的基础性工作将是关键,但这家芯片制造商也在各种渠道中播种努力。以ONNX为例,这是英特尔正在推动的AI开源容器格式;该公司还努力将VPU的低功耗加速暴露给基于Web的应用程序。该公司还与开放广播系统(OBS)、Audacity和Blender等关键实用程序合作,创建插件,使这些开创性的软件能够利用VPU。
此外,该公司还拥有自己的用于人工智能的OpenVINO工具栈,围绕着将工作负载映射到不同的磁贴并针对不同引擎优化工作负载。英特尔还与许多ISV合作,这些ISV将能够使用VPU来帮助获得一般的人工智能体验。今天,这些例子包括在不破坏前景对象的情况下应用背景模糊,这实际上是相当计算密集的。
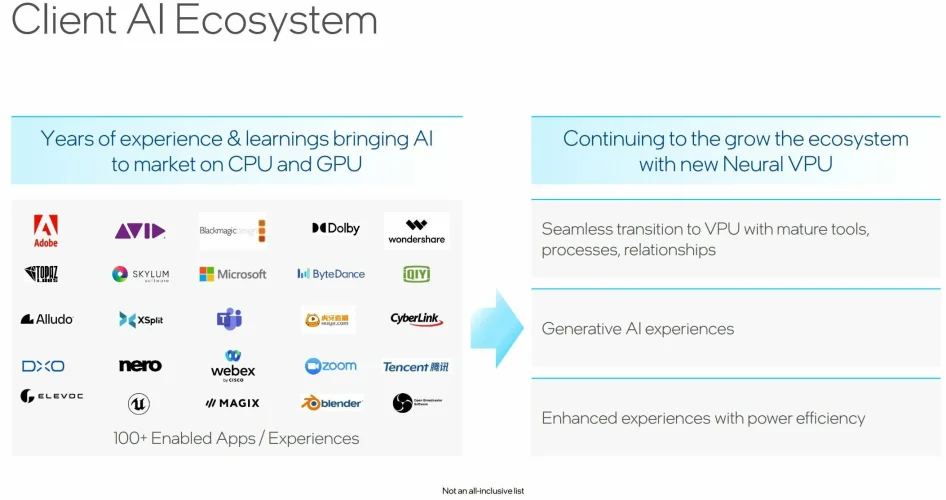
这一点,再加上开源的努力,是拼图中必要的一块。“其中75%以上是软件问题,”雷菲尔德说。“我们主要是一家硬件公司,但问题主要出在软件方面。”
有话要说...