如何免费(和私下)运行自己的类似ChatGPT的LLM
- 技术相关
- 1年前
- 129
- 更新:2024-01-24 15:22:37

像ChatGPT这样的大型语言模型(LLM)的力量是显而易见的,通常通过云计算实现,但你有没有想过在自己的笔记本电脑或台式机上运行AI聊天机器人?根据您的系统的现代化程度,您可能可以在自己的硬件上运行LLMS。但你为什么要这么做呢?

好吧,也许您想要针对您自己的数据微调一个工具。也许你想让你的人工智能对话保持私密和离线。你可能只想看看人工智能模型能做什么,而不是运行云服务器的公司关闭他们认为不可接受的任何对话话题。在您自己的硬件上使用类似ChatGPT的LLM,所有这些场景都是可能的。
硬件并不像你想象的那样是个障碍。最新的LLM经过优化,可以与NVIDIA显卡和使用Apple M系列处理器的Mac电脑一起使用-甚至是低功耗的覆盆子PI系统。随着新的专注于人工智能的硬件上市,比如英特尔“流星湖”处理器的集成NPU或AMD的Ryzen AI,本地运行的聊天机器人将比以往任何时候都更容易获得。
多亏了拥抱脸这样的平台和Reddit的LocalLlaMA这样的社区,ChatGPT等轰动一时的工具背后的软件模型现在已经有了开源的等价物–事实上,在撰写本文时,有超过20万种不同的模型可用。此外,多亏了Oobaboga的文本生成WebUI等工具,你可以在浏览器中使用类似于ChatGPT、Bing Chat和Google Bard的干净、简单的界面来访问它们。
因此,简而言之:本地运行的人工智能工具是免费提供的,任何人都可以使用它们。然而,它们都不是为非技术用户现成的,而且这一类别足够新,您不会找到许多关于如何下载和运行您自己的LLM的易于消化的指南或说明。同样重要的是要记住,本地LLM不会像云服务器平台那样快,因为它的资源仅限于您的系统。
然而,我们在这里帮助好奇的人,一步一步地指导你在自己的电脑上设置自己的ChatGPT替代方案。我们的指南使用的是Windows计算机,但这里列出的工具通常也适用于Mac和Linux系统,尽管在使用不同的操作系统时可能会涉及一些额外的步骤。
有关在本地运行LLMS的一些警告
然而,首先,有几个警告–划掉,很多警告。正如我们所说的,这些模型是免费的,由开源社区提供。他们依赖于许多其他软件,这些软件通常也是免费和开源的。这意味着一切都是由单独的程序员和志愿者团队以及Facebook和微软等几家大公司共同维护的。重点是你会遇到很多移动部件,如果这是你第一次使用开源软件,别指望它会像在手机上下载一个应用程序那么简单。相反,这更像是在你还没有考虑下载你想要的最终应用程序之前就安装了一堆软件–然后可能仍然无法工作。而且,无论我们试图使这本指南多么全面和用户友好,您可能会遇到我们不能在一篇文章中解决的障碍。
此外,寻找答案也可能是一件真正的痛苦。致力于这些主题的在线社区通常有助于解决问题。通常,有人已经解决了你在网上通过搜索就能找到的对话中遇到的问题。但这段对话在哪里呢?它可能在Reddit上、在FAQ中、在GitHub页面上、在HuggingFace的用户论坛上,或者在其他完全不同的地方。
值得一提的是,开源人工智能发展迅速。每天都有新的模型发布,用于与它们互动的工具几乎同样频繁地变化,基本的训练方法和数据以及所有支撑这一点的软件也是如此。作为一个可以写作或潜水的话题,人工智能是流沙。一切都在快速变化,环境也在不断地经历着巨大的变化。因此,在更新和更好的LLM和客户端发布之前,这里讨论的许多软件可能不会持续很长时间。
一句话:风险自负。开源软件没有极客小组可以求助;也不是完全由专业人员维护;你也不会发现可以阅读的方便手册,也没有客户服务部门可以求助–只有一堆组织松散的在线社区。
最后,一旦你运行了所有这些人工智能模型,这些模型都有不同程度的润色,但它们都带有相同的警告:不要相信它们表面上说的话,因为它往往是错误的。永远不要指望人工智能聊天机器人帮助你做出健康或财务决策。同样的道理也适用于写你的学校论文或你的网站文章。此外,如果人工智能说了一些冒犯的话,尽量不要把它当成是针对个人的。它不是一个做出判断或说出有问题的意见的人;它是一个统计单词生成器,用来吐出大多数容易辨认的句子。如果这一切听起来太可怕或乏味,这可能不是一个适合你的项目。
选择您的硬件
在开始之前,您需要了解一些关于您想要在其上运行LLM的机器的信息。它是Windows PC、Mac还是Linux机顶盒?本指南将再次侧重于Windows,但参考的大多数资源都为其他操作系统提供了其他选项和说明。
您还需要知道您的系统是否具有独立的GPU或依赖其CPU的集成显卡。大量开源LLM可以仅在您的CPU和系统内存上运行,但大多数LLM都是为了利用专用图形芯片的处理能力及其额外的视频RAM而设计的。游戏笔记本电脑、台式机和工作站更适合这些应用程序,因为它们拥有这些型号经常依赖的强大图形硬件。

在我们的案例中,我们使用的是联想Legion Pro 7i Gen 8游戏笔记本电脑,它结合了强大的英特尔酷睿i9-13900HX CPU、32 GB系统RAM和强大的NVIDIA GeForce RTX 4080移动图形处理器以及12 GB专用VRAM。
如果您使用的是Mac或Linux系统,依赖于CPU,或者正在使用AMD而不是Intel硬件,请注意,虽然本指南中的一般步骤是正确的,但您可能需要额外的步骤和其他或不同的软件来安装。你看到的表现可能与我们在这里讨论的截然不同。
设置您的环境和所需依赖项
要开始,你必须下载一些必要的软件:Microsoft Visual Studio 2019。任何更新的Visual Studio 2019版本都可以运行(尽管不是较新的年化版本),但我们建议直接从Microsoft获取最新版本。
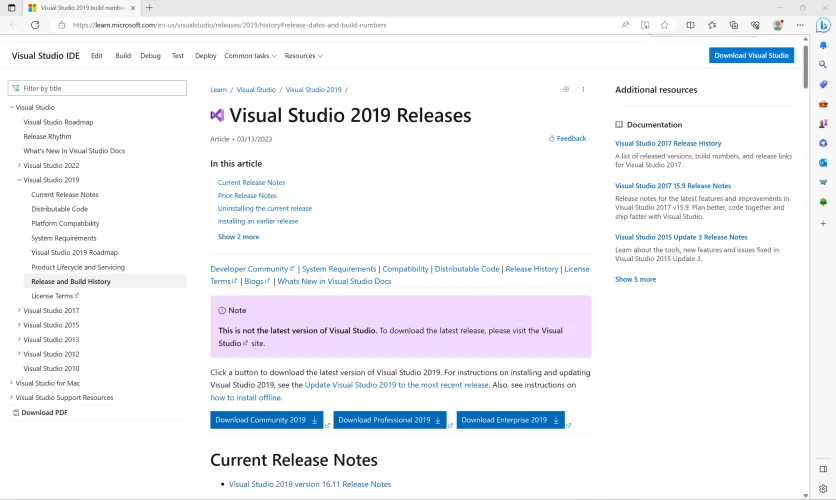
个人用户可以跳过企业版和专业版,只使用BuildTools版本的软件。
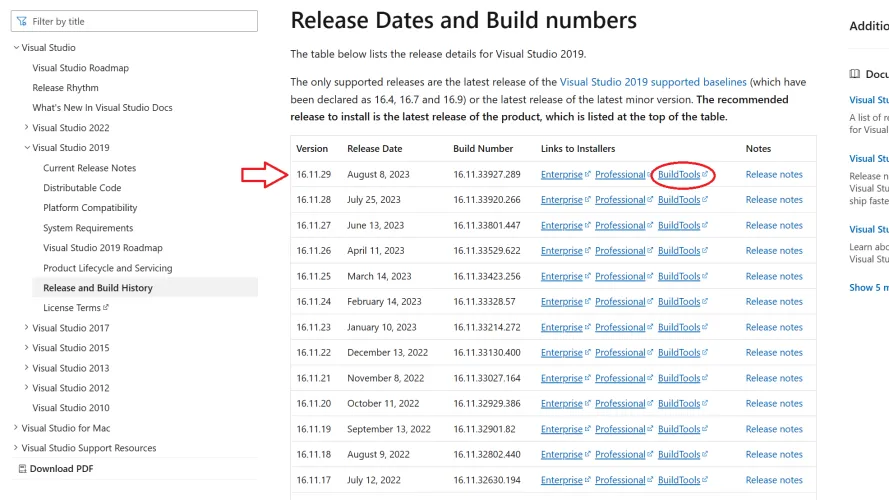
选择该选项后,确保选择“使用C++进行桌面开发”。要使其他软件正常工作,这一步骤是必不可少的。
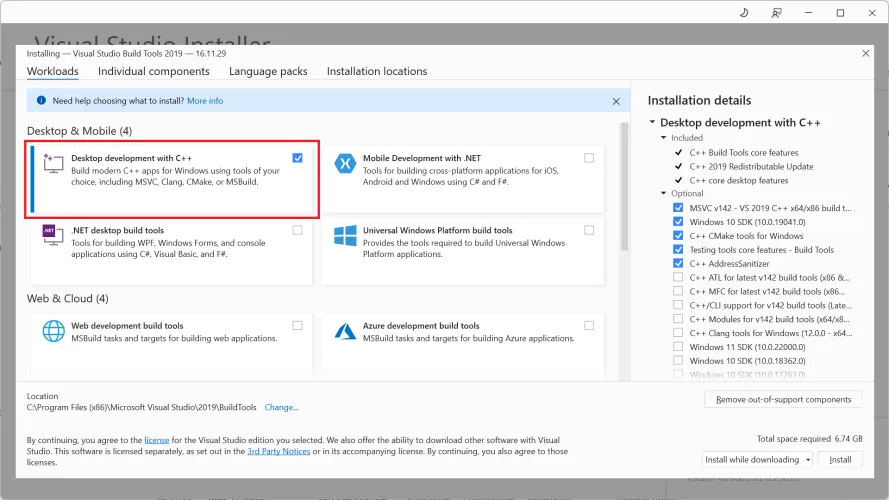
开始下载并重新启动:根据您的互联网连接,软件可能需要几分钟才能启动。
下载Oobaboga的文本生成WebUI安装程序
接下来,您需要从Oobaboga下载文本生成WebUI工具。(是的,这是一个愚蠢的名字,但GitHub项目为人工智能提供了一个易于安装和使用的界面,所以不要被这个名字所困扰。)
要下载该工具,你可以浏览GitHub页面,也可以直接转到Oobbooga提供的一键安装程序集合。我们已经安装了Windows版本,但您也可以在这里找到Linux和MacOS的安装程序。下载如下所示的压缩文件。

在你的电脑上某个你会记住的地方创建一个新的文件夹,并将其命名为AI_Tools或类似的名称。不要在文件夹名称中使用任何空格,因为这会扰乱安装程序的一些自动下载和安装过程。
然后,将刚刚下载的压缩文件的内容解压缩到新的AI_Tools文件夹中。
运行文本生成WebUI安装程序
将压缩文件解压缩到新文件夹后,查看其中的内容。您应该会看到几个文件,包括一个名为startwindows.bat的文件。双击它以开始安装。
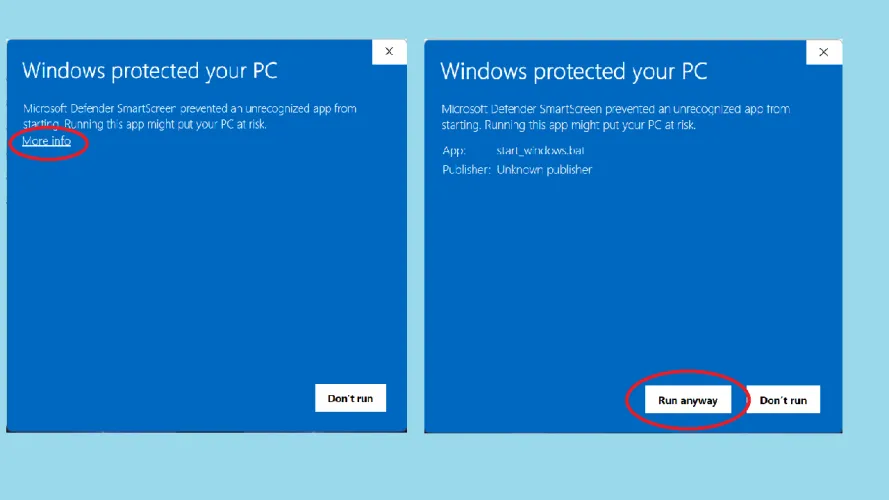
根据您的系统设置,您可能会收到有关Windows Defender或其他安全工具阻止此操作的警告,因为它不是由公认的软件供应商提供的。(我们没有经历或看到任何在线报告表明这些文件有任何问题,但我们重申,您这样做的风险自负。)如果要继续,请选择“更多信息”以确认是否要运行startwindows.bat。单击“仍要运行”以继续安装。
现在,安装程序将打开命令提示符(CMD)并开始安装运行文本生成WebUI工具所需的数十个软件。如果您不熟悉命令行界面,只需静观其变。
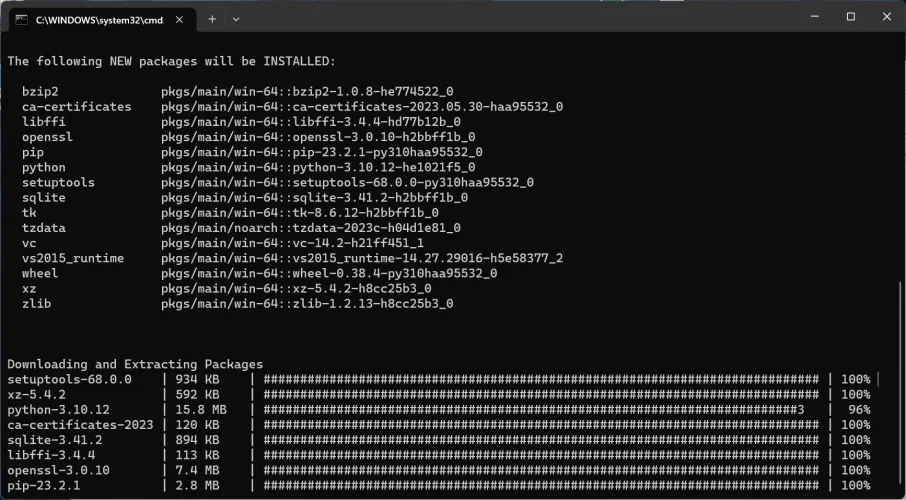
首先,你会看到许多滚动的文本,然后是由标签或英镑符号组成的简单进度条,然后会出现一个文本提示。它会问你的GPU是什么,让你有机会指出你是在使用Nvidia、AMD或Apple M系列芯片,还是只使用了一个CPU。在下载任何东西之前,你应该已经弄清楚这一点。在我们的例子中,我们选择A,因为我们的笔记本电脑配备了NVIDIA图形处理器。
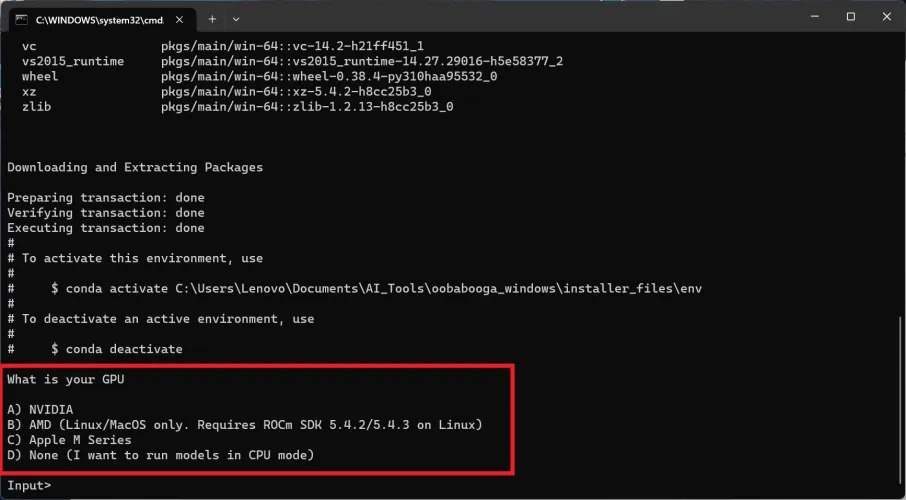
一旦你回答了问题,安装程序就会处理剩下的事情。你会看到大量的文本滚动,然后是简单的文本进度条,然后是更形象的粉色和绿色进度条,因为安装程序下载并设置了它所需的一切。
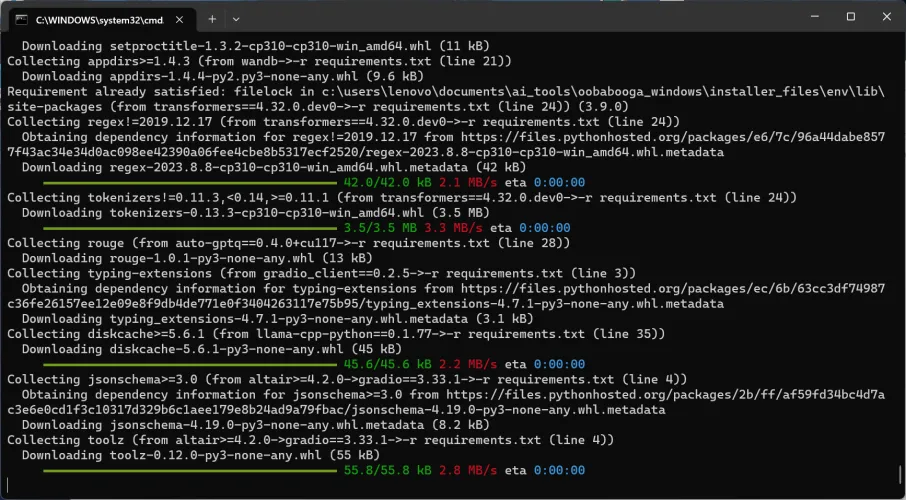
在此过程结束时(可能需要长达一个小时),您将看到一条由星号包围的警告消息。该警告将告诉您尚未下载任何大型语言模型。真是个好消息!这意味着文本生成WebUI的安装即将完成。
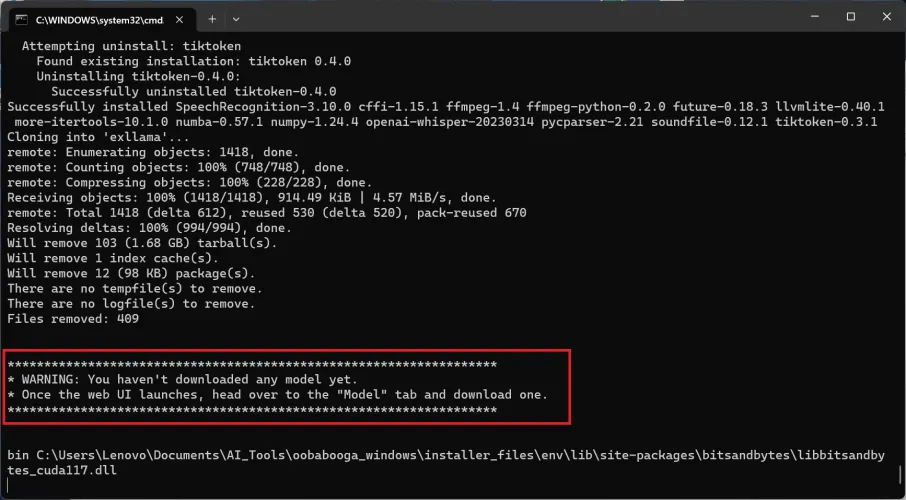
此时,您将看到一些绿色文本,上面写着“信息:正在加载扩展库”。您的安装已完成,但不要关闭命令窗口。
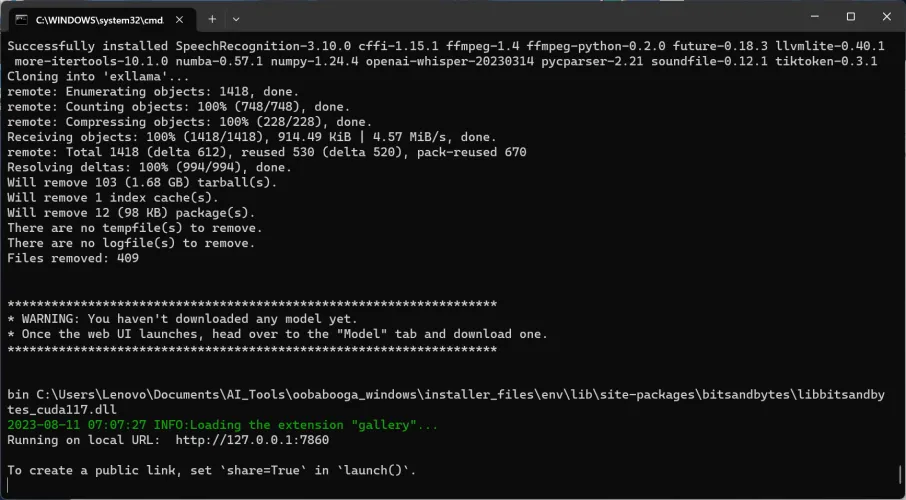
复制并粘贴WebUI的本地地址。
在绿色文本的正下方,您将看到另一行内容为“Running on local url:http://127.0.01:7860.”只需点击URL文本,它将打开您的Web浏览器,显示文本生成WebUI-您的所有LLM界面。
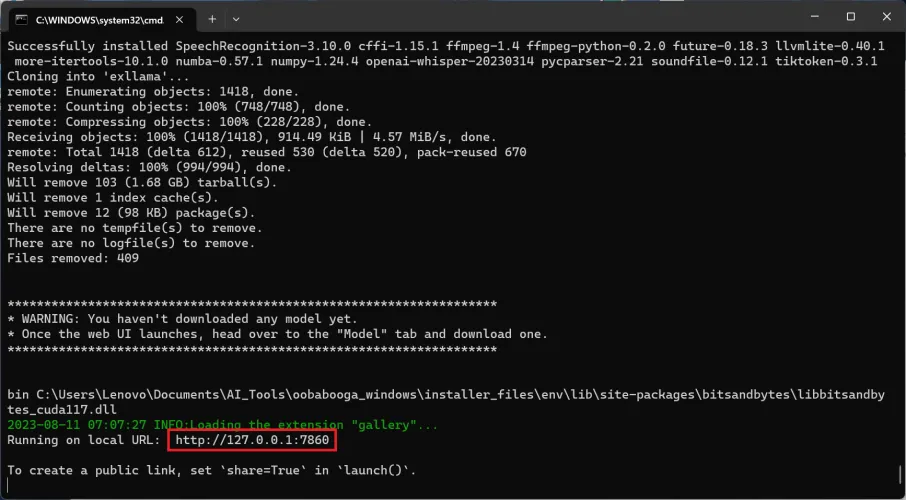
您可以将此URL保存在某个位置或在浏览器中将其添加为书签。尽管文本生成WebUI是通过浏览器访问的,但它在本地运行,因此即使您的Wi-Fi关闭,它也会运行。此Web界面中的所有内容都是本地的,生成的数据应该是您和您的计算机的私有数据。
关闭并重新打开WebUI
成功访问WebUI以确认其安装正确后,继续并关闭浏览器和命令窗口。
在您的AI_Tools文件夹中,打开我们用来安装所有东西的相同的Start_Windows批处理文件。它将重新打开CMD窗口,但不是完成整个安装过程,而是加载一些文本,包括中的绿色文本,然后告诉您扩展库已加载。这意味着WebUI已准备好在您的浏览器中再次打开。
使用之前复制或添加书签的相同本地URL,WebUI界面将再次向您致意。这就是您将来打开该工具的方式,让CMD窗口在后台打开。
选择并下载LLM
现在您已经安装并运行了WebUI,是时候找到要加载的模型了。正如我们所说的,你会发现数以千计的免费LLM可以下载并与WebUI一起使用,安装一个的过程非常简单。
如果你想要一个最推荐车型的精选列表,你可以查看一个社区,比如Reddit‘s/r/LocalLlaMA,其中包括一个社区维基页面,其中列出了几十个型号。它还包括有关构建不同型号的信息,以及有关不同硬件支持哪些型号的数据。(一些LLM专门用于编码任务,而另一些则是为自然文本聊天而构建的。)
这些清单最终都会把你送到拥抱脸,那里已经成为了LLM和资源的储存库。如果你从Reddit来到这里,你可能会被直接指向一个型号卡,这是一个关于特定可下载型号的专用信息页面。这些卡片提供一般信息(如使用的数据集和培训技术)、要下载的文件列表和社区页面,人们可以在其中留下反馈以及请求帮助和错误修复。
在每个型号卡片的顶部都有一个大的、粗体的型号名称。在我们的案例中,我们使用了Eric Hartford制造的WizardLM7B未经审查的模型。他使用了网名ehartford,所以模特的列出位置是“ehartford/WizardLM-7B-Uncensired”,就像它在模型卡片顶部列出的那样。
标题旁边是一个小复制图标。点击它,它会将格式正确的模型名称保存到您的剪贴板。
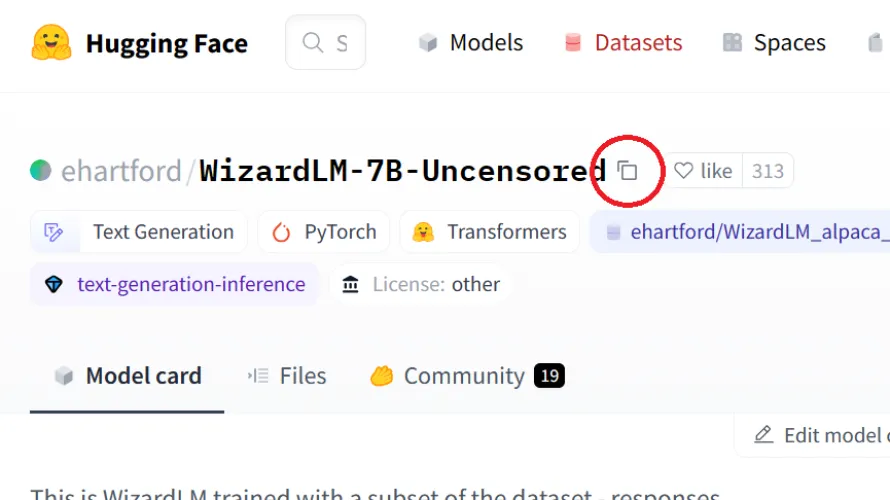
回到WebUI,转到Model选项卡,并在标记为“Download Customer Model or Lora”的字段中输入该模型名称。粘贴型号名称,点击下载,软件将开始从拥抱脸下载必要的文件。

如果成功,您将在WebUI窗口中看到一个橙色的进度条弹出,并且在您在后台打开的命令窗口中将出现几个进度条。
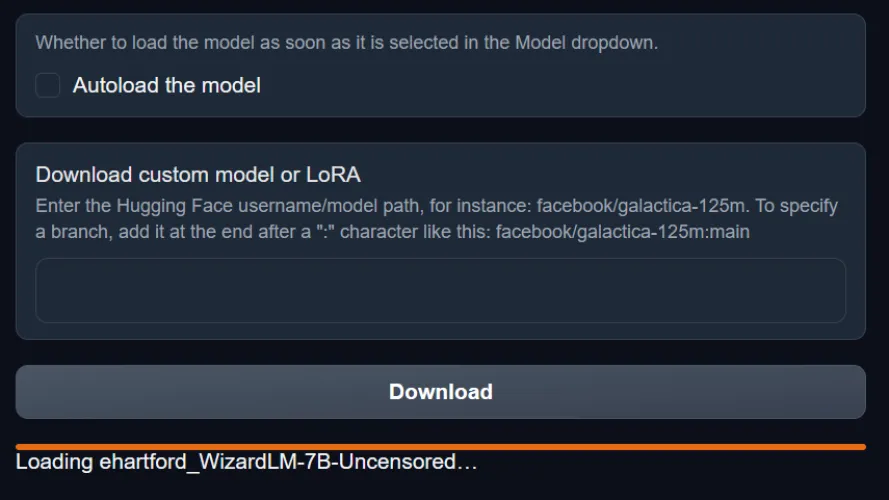
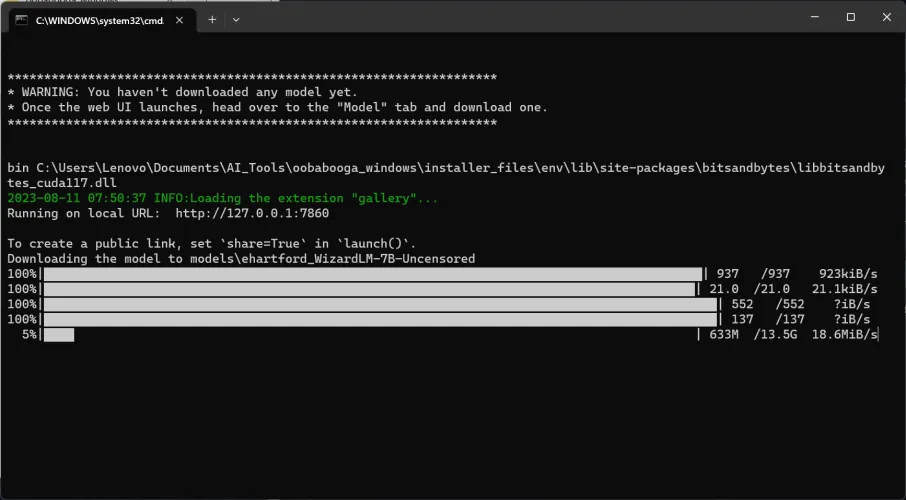
一旦完成(同样,请耐心等待),WebUI进度条将消失,它将简单地显示“完成!”取而代之的是。
在WebUI中加载模型和设置
下载模型后,需要将其加载到WebUI中。为此,请从模型选项卡左上角的下拉菜单中选择它。(如果您下载了多个型号,则需要在此处选择要使用的型号。)
在使用该模型之前,需要分配一些系统或图形内存(或两者)来运行该模型。虽然你可以在这些模型中调整和微调几乎任何你想要的东西,包括内存分配,但我发现将其设置为大约三分之二的GPU和CPU内存效果最好。这为您的其他PC功能留下了足够的未使用内存,同时仍为LLM提供了足够的内存来跟踪和保持更长的通话时间。
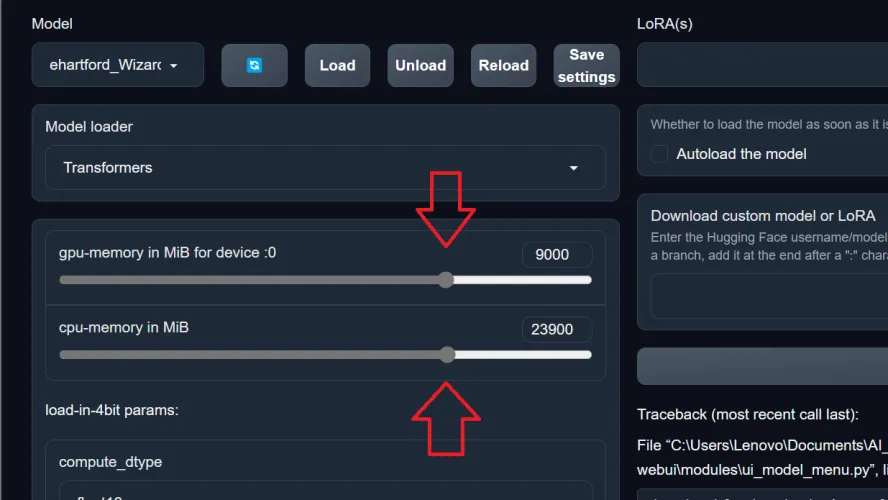
一旦您分配了内存,点击保存设置按钮保存您的选择,它将默认为该内存分配每次。如果您想更改它,只需将其重置并再次按下保存设置即可。
好好享受你的LLM吧!
你的模型装好了,准备好了,是时候开始和你的ChatGPT替代品聊天了。在WebUI中导航到文本生成选项卡。在这里,您将看到与AI聊天的实际文本界面。在框中输入文本,按Enter键发送文本,然后等待机器人响应。
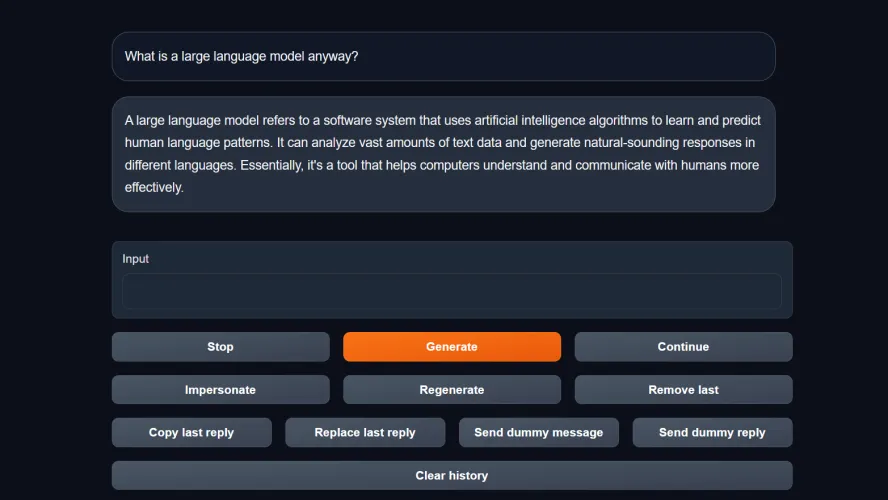
在这里,我们再说一遍,你会体验到一点失望:除非你使用的是具有多个高端GPU和海量内存的超级出色的工作站,否则你的本地LLM不会像ChatGPT或Google Bard那样快。机器人将一次吐出一个单词片段(称为令牌),每个单词之间都有明显的延迟。
然而,只要有一点耐心,你就可以与你下载的模型进行充分的对话。你可以向它询问信息,玩基于聊天的游戏,甚至给它一个或多个个性。此外,您可以使用LLM,确保您的对话和数据是隐私的,这可以让您高枕无忧。
在开始学习本地LLM时,您会遇到大量的内容和概念供您探索。随着您越来越多地使用WebUI和不同的模型,您将更多地了解它们的工作原理。如果你不知道你的文本和令牌,或者你的GPTQ和LORA,这些是开始沉浸在机器学习世界中的理想地方。



有话要说...